Documentation
I love documentation. But also, documentation is the worst. Making documentation is hard. Making great documentation even harder. But it is instrumental to helping your code be useful to people that aren’t you, and that’s a worthwhile pursuit! Even if you’re making things just for yourself, the people that aren't you descriptor also includes you in a few years/months/weeks, who has no idea what you were even thinking.
These are the notes that I’m making while reworking the documentation for semantic.works.
Design principles
- Don’t Repeat Yourself. If we’re copying documentation across places, we’re doing something wrong.
- Good. The Divio documentation principles should apply.
- Ease of use: writers. Minimising maintenance for the people who make the code is essential. Having them sign in to a whole different platform to write the documentation for their code would be way too much friction.
- Ease of use: readers. We have a bunch of projects going on, written in Ruby, Lisp, Elixer, JavaScript, Python… The documentations should resemble eachother and be consistent.
- Micro-first. Semantic.works is about microservices, so that means there’ll be a bunch of documentation which is small. And that’s okay! But it is important to not build the base structure to accommodate big projects. A documentation folder for something that can be explained in one README is a no-go. Start from a single file, and expand only if necessary.
- Non-proprietary. It should be able to move, not be bloated. No editor lock-in, no host lock-in.
Sidequest: automated generation
There are a doc generators! JSDoc is my favourite just for its syntax alone.
But ruh roh, did you read the first two letters of that name? A lock-in to a programming language. Yes, we could find a documentation generator for every language we use, but then we will semi-break 3., but mostly full break 4.. Unless we morph every of those generators to the same output. Also breaking 4..
How about the general purpose ones?
Yes! There are two really cool options. First was Doxygen: a seemingly cool tool with a bunch of supported languages! But a few of our common ones are missing, so I feel like a fool.
Then Dexy. You can see the remains of my tests with it (including Dockerising it) in the files listed here. But to give you the gist: it is a super extendible and really cool amalgemation of text processing, bundled into a pretty easily configurable yaml. Jinja, pandoc and markdown are but a few of the impressive list of built-in tools. Sadly, while it can run a bunch of languages and grab the output, it seems to lack the ability to dissect the code you give it in any meaningful ways. This bundled with a website that is split across domains and a lack of updates in the last few years, make it sub-ideal for what I’m trying to do.
Dexy files
Updating existing documentation
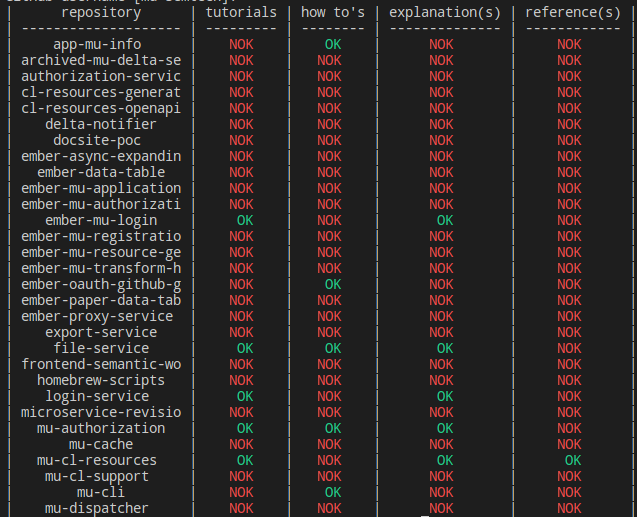
Well first I had to know which repos to update! So of course I made an script for it.
1 | python3 diviocheck.py |
(You can run it locally! It has no dependencies except Python3 itself and its native libraries)
Returned the following:
Sidequest: documentation structuring
So. Cat from a bit in the future. I’ve started importing blog posts from mu.semte.ch, because (ignoring the bias that I work for them) they’re pretty darn good at explaining the concepts.
Challenges
I: bloat
Now look at the README in this commit and despair.
Something is awry. This is too big.
II: ordering
The README from above also includes another goofy problem: the order of information. Having a singular README is consise in terms of writing, but the references explanations on the bottom of the document might be good reading material before starting. Splitting up this README into multiple would perhaps be a bit asinine: its a project template, it shouldn’t be filled with docs/ folders. But it should also easily link to all this info, right?
#### III: order in the orderingBut we can’t just move the docs to wherever. Using readthedocs crossedNow there’s also an interesting conundrum. What about (i forgot what i was writing about)
Solutions
This section will refer to
- Documentation that should be kept as close as possible) as (essential) documentation. This is the documentation that would be required to have even for people familiar with the project. How to start up the application, which license…
- Documentation that could be expected in a seperate file or link as extra documentation.
By seperating these two, we can more easily interlink between documentation. mu-semtech is built on [reactive-programming](/mu-semtech/reactive-programming), or this tutorial
Readthedocs
Pros:
- It seems to support markdown alongside .rst
- It’s a familiar layout for most developers
Cons:
- Reliance on an external service
- Requires permissions on the user/org
- Some external configuration needed (.yaml file, website)
- Not easily adaptable
Documentation in project repo
Documentation in a dedicated repo
We could also have a docs repo, where all extra documentation is kept.
Pros:
- Easily moveable
- Easily adaptable
Cons:
- More friction in upkeep
But, what if the friction could be removed?
Note: the rest of this section has been moved to its own repo oh no.